Background
High-performance image generation models are shifting from inefficient multi-step samplers to efficient few-step counterparts. These step-distilled diffusion models are attractive in practical production settings because they reduce the number of function evaluations while preserving, and often improving, generation quality.
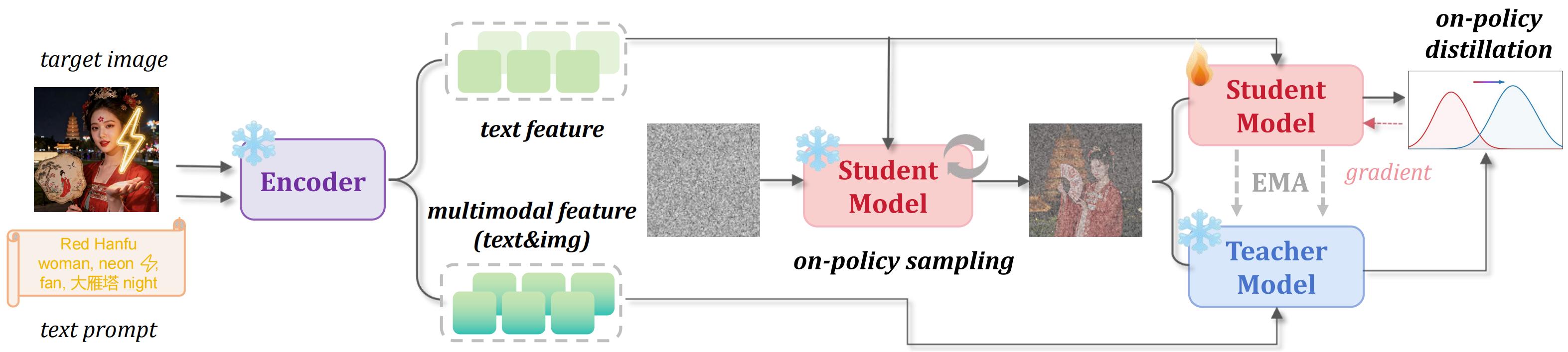
However, how to continually tune such models remains unclear.

Vanilla SFT provides supervision through ground-truth velocity, but it is off-policy and lacks train-inference state consistency. Offline RL-style methods such as Diffusion-DPO or PSO introduce pairwise supervision, yet their optimization states and supervision signals are still not fully induced by the student's current distribution. Online RL-style methods better preserve few-step behavior by training on model roll-outs, but they depend on reward functions or reward models that are often unavailable for secondary developers who only have image-text pairs.
D-OPSD occupies a different point in this design space: it is on-policy, does not require a reward model, preserves train-inference consistency, and still incorporates target image-text pairs through self-distillation.